
This blog post is a recap of the presentation “Lies, Damned Lies, and Search Marketing Statistics” given by Vistaprint SEO Manager (North America, Australia, New Zealand) Adria Kyne at the SMX Advanced Conference in Seattle, June 2016. During this presentation, Adria touches on the use of Bayesian methods to infer the results of an A/B test.

Thomas Bayes
Her point was that the sample size for A/B testing is often too small and experiments are ended too early to be statistically significant. So, before prematurely acting on results we must understand the likelihood that any performance differences we observe are due only to chance rather to the change we are testing.
To this end, Bayesian methods help avoid common pitfalls of statistical testing and make analysis and results easier to understand while enabling better decision-making.
Bayesian Inference
Bayesian inference is used during statistical modeling to update the probability of a hypothesis based upon ongoing data collection. In short, using Bayesian methods allows for communicating that there is a “90% probability that campaign B performs better than campaign A”.
It starts with identifying prior beliefs – or “prior” – about what results are likely, and then updating those according to the data collected. For example, if the current conversion rate is 5% it is very unlikely to achieve a conversion rate higher than 20%:
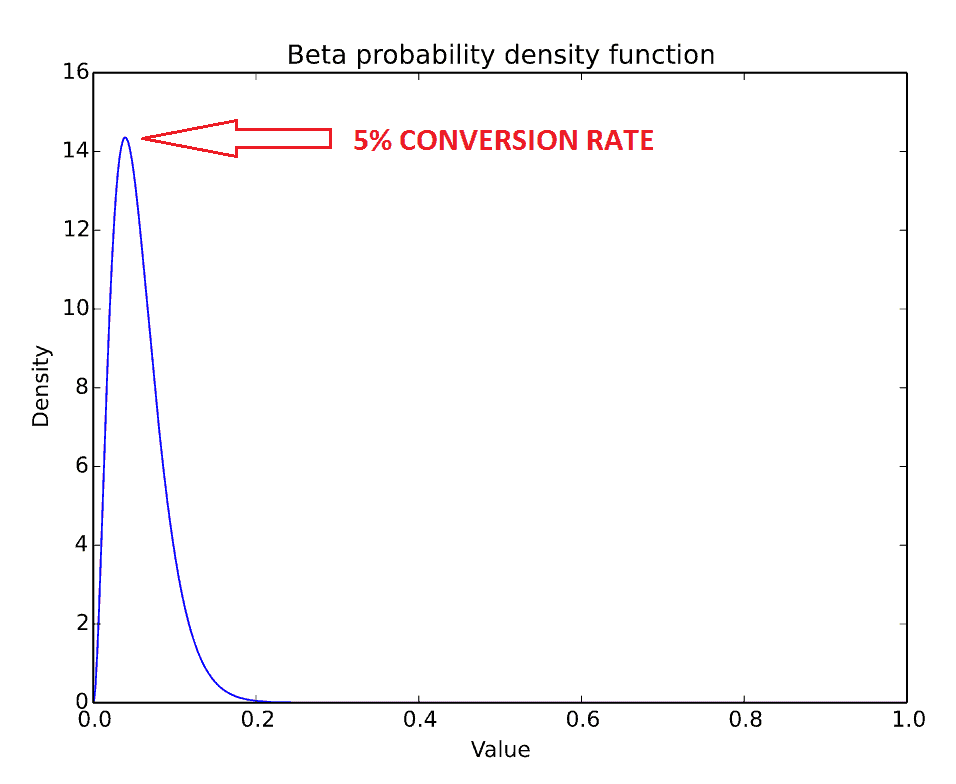
X: Conversion rate as a percentage; Y: Probability density
As the data begin compiling, the beliefs are updated. If the incoming data points signal an improvement in the conversion rate, the estimate of the effect can be moved from the prior upwards; the more data that is collected, the more confident one can be in the results moving away from the prior – then called a “posterior”, or the likely distribution of the effect.

X: Conversion rate as a percentage; Y: Probability density
Bayes’ Theorem actually allows for stopping a test at any time if there is a clear winner or run it for longer if more samples are needed. In Bayesian testing, outputs are easily interpreted quantities – for example, the probability that version A is better than version B.
The more popular alternative to Bayesian inference is classical significance testing, which draws conclusions based on the data sets’ comparison to a null hypothesis
There is a great article on Lyst’s engineering blog that goes more in depth on the subject of Bayesian A/B testing.
Case Study
The objective is to test EveryMundo’s proprietary Dynamic Price Insertion in ad copy and analyze the results using Bayesian Inference.
Set Up
Dynamic Price Insertion is a new product that EveryMundo has built which allows for inserting the lowest fare in an airline’s ad copy for every route in real-time. To test the tool’s efficacy, an experiment was necessarily set up. The goal of the ongoing experiment is to determine if dynamically surfaced data performs better in ads than a static ad.
The ad copy tested was exactly the same for control and experiment, except that a price was added to the headline of the ad copy of the experiment.
Control:
Static ad for flights from Athens to London
Experiment:

Dynamic Price Insertion of €62 in same ad for flights from Athens to London
Analysis of Results using Bayesian Calculator
The test is still very young as the experiment has been running for four days only. However, we can use Bayesian Inference to determine what the probability of the experiment performing better at this moment than the control.
Using a Bayesian calculator can provide insight as to the outcomes of A/B testing, even when signals are weak. There are different online Bayesian calculators, but here is the one used for this analysis and an accompanying description of the underlying principles of the calculator.
The results show that after running the experiment for four days only that the probability of the ad copy with dynamic price insertion performing better than the static ad copy is 54%.
| Version | Description | Trials (Impressions) | Successes (Conversions) | ~ Prob.of being best |
| Control | Static-Low Price | 82,710 | 9 | 46% |
| Experiment | Dynamic Price Insertion | 52,974 | 6 | 54% |
Conclusion
Using Bayesian Methods is a great communication and A/B testing analysis tool to better understand marketing results. If we would stop our experiment right now, the probability of the experiment performing better than the original static ad copy is 54%. Bayesian methods allow for getting results and drawing inferences at any time. The experiment has only run for four days, but we are already able to draw conclusions using these methods. However, by continuing to collect more data, the level of confidence in the results will grow meaning we can move further away from our prior.